
Stable Diffusion remains one of the most popular open-source image generation models, and accessing it through an API is the fastest way to integrate it into your products and workflows. Wireflow lets you chain Stable Diffusion with other models in a visual canvas and expose the entire pipeline as a single API endpoint. Below, we break down the seven best tools for accessing Stable Diffusion via API in 2026, covering pricing, supported model versions, and developer experience.
- Wireflow - Best overall (visual workflows + unified API)
- Stability AI - Official API from the model creators
- Replicate - Pay-per-prediction open-source model hosting
- FAL AI - Fast inference with serverless GPUs
- Together AI - High-throughput batch inference
- Fireworks AI - Low-latency optimized serving
- DeepInfra - Budget-friendly inference at scale
1. Wireflow
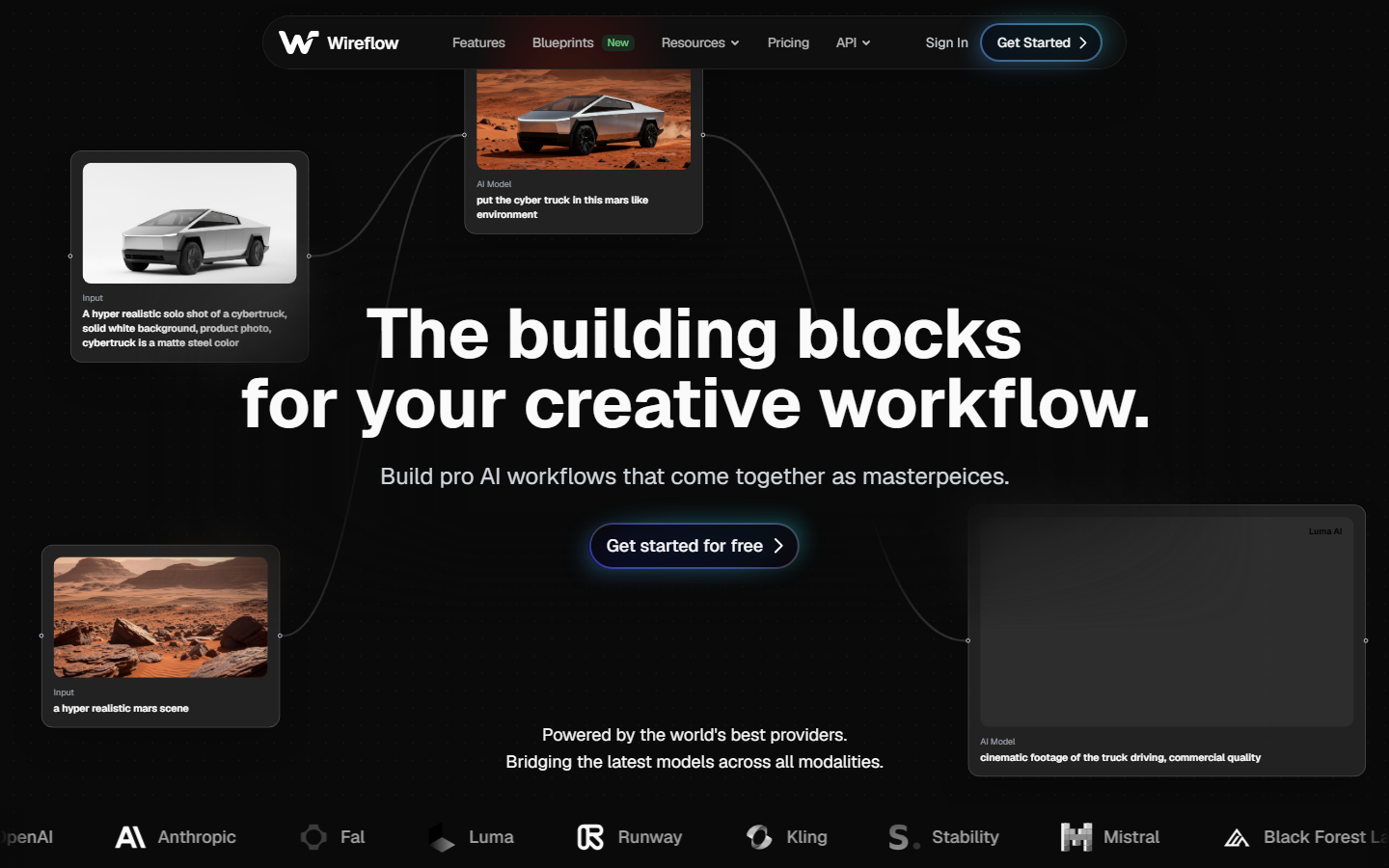
Wireflow is a visual node-based platform that lets you build multi-step AI pipelines without writing backend code. You can drop a Stable Diffusion node onto the canvas, connect it to upscalers, background removers, or video generators, and then call the whole chain through a single REST endpoint. Every node executes on managed GPUs, so there is nothing to provision. For a hands-on look at this in action, check out the Stable Diffusion API workflow on Wireflow.
Key strengths: visual node editor for chaining models, one-click API deployment, built-in version control, and usage-based pricing with no per-seat fees.
Pricing: Free tier available. Pay-as-you-go starts at $0.01 per generation step. See full details on the pricing page.
2. Stability AI
Stability AI is the company behind Stable Diffusion. Their official API provides access to SDXL, SD3, and newer models through a straightforward REST interface. In 2026, Stability shifted focus toward enterprise contracts, which means individual developers may find the free tier more limited than before. The API documentation is solid, and you get access to the latest model checkpoints before they hit open-source repos.
Key strengths: first-party access to new model versions, enterprise SLAs, fine-tuning endpoints. The platform supports batch image generation natively for high-volume use cases.
Pricing: Credit-based system. SDXL starts around $0.002 per image at lower resolutions. Enterprise plans available on request.
3. Replicate
Replicate hosts thousands of open-source models, including every major Stable Diffusion variant. You push a prediction request, Replicate spins up a GPU, runs inference, and returns the result. The developer experience is among the best in the space: clean docs, webhook support, and client libraries for Python and JavaScript. Since Cloudflare acquired Replicate in late 2025, cold-start latency has improved significantly thanks to edge-cached model weights.
Key strengths: massive model library, webhook callbacks, versioned model endpoints. If you are building an AI content generation API, Replicate's model variety gives you broad flexibility.
Pricing: Pay per second of compute. SDXL runs cost roughly $0.003 to $0.01 per image depending on resolution and steps.
4. FAL AI
FAL AI focuses on speed. Their serverless GPU infrastructure keeps popular models warm, so cold starts are rare. SDXL inference typically completes in under two seconds. FAL also supports LoRA loading at request time, which is useful if you have custom-trained adapters. The API is OpenAPI-spec compliant, making it easy to integrate with tools that generate client code automatically, similar to how headless AI workflow platforms expose standardized endpoints.
Key strengths: sub-2s latency, LoRA hot-loading, streaming output, OpenAPI spec.
Pricing: Pay per second. SDXL inference starts around $0.002 per image.
5. Together AI
Together AI is built for throughput. If you need to generate hundreds or thousands of images in a batch job, Together's infrastructure handles it without queueing delays. They support SDXL and Flux models alongside their LLM offerings, so you can consolidate your AI API spend under one provider. Their dedicated endpoints option lets you reserve GPU capacity for predictable workloads, comparable to what an AI orchestration API offers for multi-model pipelines.
Key strengths: high-throughput batch mode, dedicated GPU reservations, combined LLM and image model access.
Pricing: Starts at $0.003 per image for SDXL. Volume discounts available.
6. Fireworks AI
Fireworks AI optimizes model serving at the kernel level. Their custom inference engine squeezes more throughput per GPU than stock implementations, which translates to lower cost per image. Fireworks supports SDXL, SD3, and community fine-tunes. The API follows standard conventions, and they offer an on-demand fine-tuning service where you upload training images and get a custom endpoint. Their approach to model optimization aligns well with building programmatic image generation at scale.
Key strengths: kernel-level optimization, on-demand fine-tuning, competitive per-image cost.
Pricing: SDXL images from $0.002. Custom fine-tune endpoints carry a small hourly surcharge.
7. DeepInfra
DeepInfra positions itself as the budget option for open-source model inference. They support SDXL and several community fine-tunes with a simple REST API. Pricing undercuts most competitors, making DeepInfra a solid choice for prototyping or low-margin applications. The trade-off is a smaller feature set: no built-in fine-tuning, fewer client libraries, and basic monitoring compared to no-code AI canvas platforms that bundle observability.
Key strengths: lowest per-image pricing, straightforward API, no minimum commitment.
Pricing: SDXL from $0.001 per image. No monthly minimums.
Comparison Table
| Platform | SDXL Support | SD3 Support | Fine-Tuning | Batch Mode | Starting Price |
|---|---|---|---|---|---|
| Wireflow | Yes (via nodes) | Yes | Yes (LoRA) | Yes | Free tier |
| Stability AI | Yes | Yes | Yes | Yes | ~$0.002/img |
| Replicate | Yes | Yes | Yes (custom models) | Yes | ~$0.003/img |
| FAL AI | Yes | Yes | Yes (LoRA hot-load) | Limited | ~$0.002/img |
| Together AI | Yes | Partial | No | Yes | ~$0.003/img |
| Fireworks AI | Yes | Yes | Yes | Yes | ~$0.002/img |
| DeepInfra | Yes | Partial | No | No | ~$0.001/img |
How to Choose the Right Stable Diffusion API
Picking the right provider depends on your use case. If you need to chain Stable Diffusion with other models (upscalers, background removers, video generators), a visual AI pipeline builder saves significant integration time. For raw throughput, Together AI and Fireworks handle high-volume jobs efficiently. If cost is the primary concern and you do not need advanced features, DeepInfra offers the lowest per-image rates.
Consider latency requirements too. FAL AI and Fireworks consistently deliver sub-2-second responses for SDXL, while batch-oriented providers like Together may queue requests during peak periods. For production applications that require API spend limits and usage controls, look for platforms that offer dashboard-level budget caps.
Try it yourself: Build this workflow in Wireflow - the nodes are pre-configured with a text-to-image pipeline using an open-source diffusion model.
FAQ
What is the Stable Diffusion API?
The Stable Diffusion API is a programmatic interface that lets developers generate images from text prompts using Stable Diffusion models without managing GPU infrastructure locally. You send an HTTP request with a prompt and parameters, and receive generated images in the response.
Is Stable Diffusion still free to use in 2026?
The model weights remain open-source and free to download. However, running inference requires GPU compute, which costs money unless you own the hardware. API providers charge per image or per second of compute time, with prices starting as low as $0.001 per image.
Which Stable Diffusion version is best for API use?
SDXL (Stable Diffusion XL) remains the most widely supported version across API providers. SD3 is available on some platforms but has more restrictive licensing. For most production use cases, SDXL offers the best balance of quality, speed, and cost.
Can I fine-tune Stable Diffusion through an API?
Yes. Stability AI, Replicate, and Fireworks AI all offer fine-tuning endpoints. You upload training images, specify parameters, and receive a custom model endpoint. FAL AI supports LoRA adapter loading at inference time, which is a lighter-weight alternative to full fine-tuning.
How fast is Stable Diffusion API inference?
Latency varies by provider and model version. SDXL inference typically takes 1 to 4 seconds depending on the provider, resolution, and number of diffusion steps. FAL AI and Fireworks AI consistently hit sub-2-second latency for standard configurations.
What is the cheapest Stable Diffusion API?
DeepInfra currently offers the lowest per-image pricing at approximately $0.001 per SDXL image. However, the cheapest option may not always be the best fit. Consider factors like latency, uptime SLAs, and feature set alongside raw pricing.
Can I use Stable Diffusion API for commercial projects?
Yes. SDXL uses an open-source license that permits commercial use. Most API providers explicitly allow commercial applications. Check individual provider terms for any restrictions on generated content ownership.
How do Stable Diffusion APIs handle NSFW content?
Most API providers include safety filters by default. Stability AI, Replicate, and FAL AI all apply content moderation. Some providers allow disabling filters for legitimate use cases (medical imaging, art), but this varies by provider and plan tier.


