
If you are building a SaaS product and want to add AI-powered image, text, or video generation directly into your app, the options in 2026 are better than ever. Wireflow provides a visual canvas and REST API that lets you chain multiple AI models into production-ready pipelines, making it one of the fastest ways to embed generative AI into any SaaS product. This guide covers the eight best platforms for the job.
For a hands-on look at this in action, check out the 'best embed AI generation in SaaS tools in 2026' feature page.
Quick Summary
- Wireflow - Best overall for visual AI pipeline building with full API access
- OpenAI API - Best for text and image generation at scale
- Anthropic Claude API - Best for long-context text generation and reasoning
- FAL AI - Best for fast, serverless image and video inference
- Replicate - Best for running open-source models via API
- Hugging Face Inference API - Best for model variety and open-source flexibility
- Fireworks AI - Best for low-latency, high-throughput inference
- Together AI - Best for fine-tuned open-source model hosting
1. Wireflow
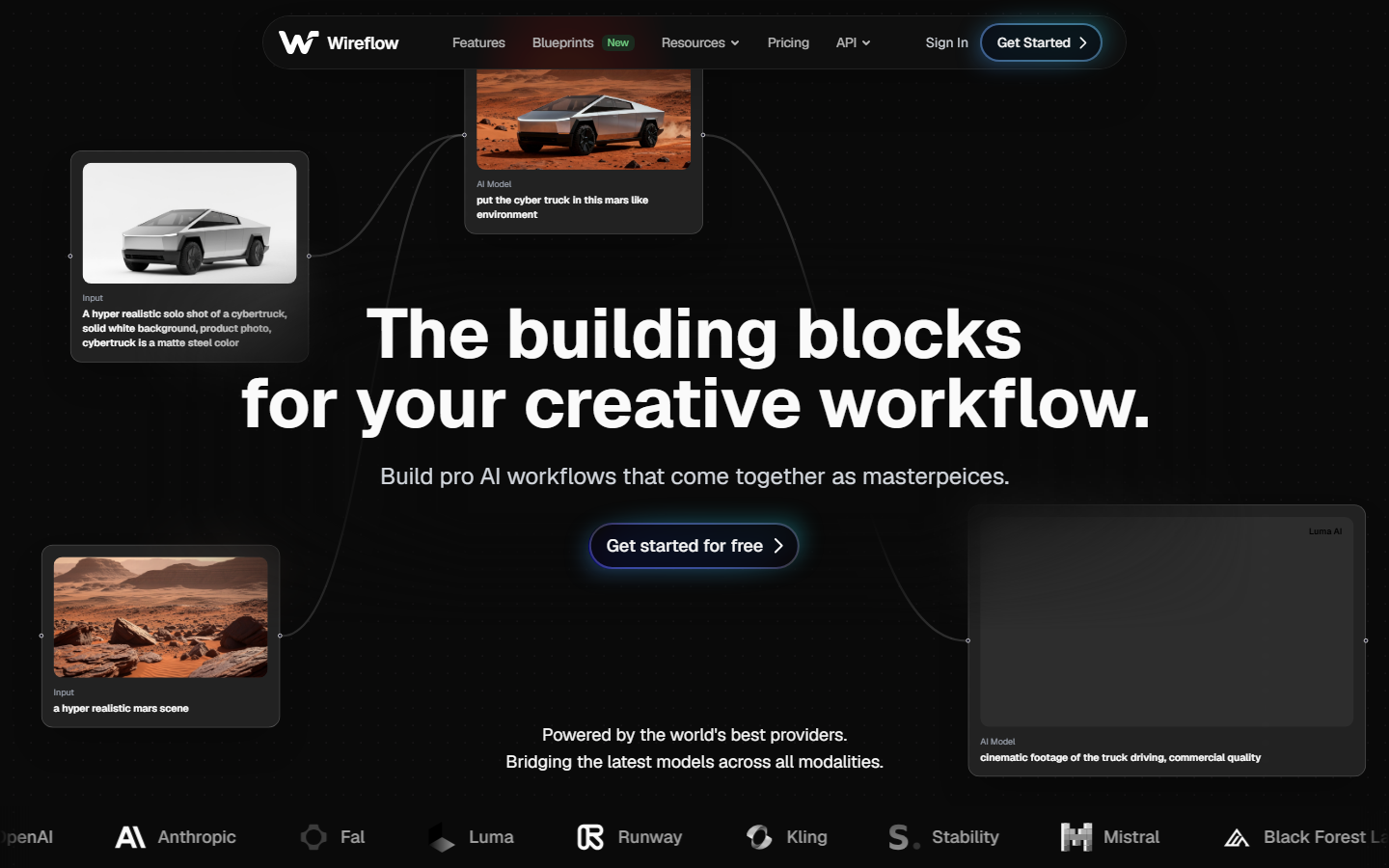
Wireflow is a visual node editor that lets SaaS teams build AI generation workflows on a drag-and-drop canvas, then expose them as a single REST API endpoint. Instead of stitching together multiple vendor SDKs, you connect nodes for text, image, video, and audio generation into one pipeline. The output is a versioned API you can call from any frontend or backend.
Key strengths
- Visual canvas for designing multi-model workflows without writing glue code
- One API endpoint per workflow, with built-in rate limiting and authentication
- Supports 30+ AI models including Recraft V4, Kling, Veo 3, FLUX, and Stable Diffusion
- Batch generation for processing hundreds of inputs in parallel
- Built-in model chaining so the output of one model feeds directly into another
Best for
SaaS teams that need to embed complex, multi-step AI generation (not just a single API call) and want to iterate visually before pushing to production.
2. OpenAI API
OpenAI remains the default choice for many SaaS builders thanks to GPT-5.4 for text, DALL-E 4 for images, and Whisper for speech-to-text. The API is well-documented, the SDKs cover every major language, and the token-based pricing scales predictably. If your SaaS workflow mainly needs text generation or simple image creation, OpenAI is the path of least resistance.
Key strengths
- Mature SDKs for Python, Node.js, Ruby, Go, and more
- Function calling and structured output for reliable integrations
- Assistants API for stateful, multi-turn conversations
- DALL-E 4 image generation with inpainting and editing
Best for
SaaS products that need reliable text generation, chat interfaces, or basic image creation with minimal integration overhead.
3. Anthropic Claude API

Anthropic offers the Claude API with models that handle up to 1 million tokens of context. This makes it the top pick for SaaS apps that process long documents, legal contracts, codebases, or multi-document research. The AI content generation API space has gotten competitive, but Claude's reasoning and safety features stand out for enterprise SaaS.
Key strengths
- 1M token context window for processing entire documents
- Tool use and computer use for agentic workflows
- Strong code generation and analysis capabilities
- Usage-based pricing with no minimum commitment
Best for
SaaS products focused on document processing, customer support automation, or applications where long context and careful reasoning matter.
4. FAL AI
FAL AI specializes in serverless AI inference with a focus on image and video generation. Cold starts are measured in milliseconds, not seconds, making it ideal for SaaS apps where users expect instant results. FAL hosts popular models like FLUX, Stable Diffusion, and Recraft, and their queue-based architecture handles traffic spikes without provisioning. If your product needs to build AI pipelines for media generation, FAL is a strong contender.
Key strengths
- Sub-second cold starts on most models
- Serverless pricing (pay only for compute used)
- Queue and webhook support for async generation
- Wide model catalog covering image, video, and audio
Best for
SaaS products that embed image or video generation and need fast, reliable inference without managing GPU infrastructure.
5. Replicate
Replicate lets you run any open-source model via a simple API. With thousands of community-contributed models and the ability to deploy custom fine-tuned models using Cog, it is the go-to platform for SaaS builders who want flexibility. The headless AI workflow approach pairs well with Replicate's prediction-based API.
Key strengths
- Thousands of pre-packaged open-source models ready to call
- Custom model deployment with Cog containers
- Webhook callbacks for async processing
- Transparent per-second GPU billing
Best for
SaaS teams that want to experiment with or deploy open-source models without managing infrastructure.
6. Hugging Face Inference API
Hugging Face hosts over 500,000 models and offers inference endpoints that scale from free tier to dedicated GPU instances. For SaaS builders evaluating multiple models before committing, Hugging Face provides the widest selection and the smoothest path from prototype to production. Their no-code AI canvas competitors are growing, but Hugging Face owns the model marketplace.
Key strengths
- Largest model hub with 500,000+ models across all modalities
- Free inference API for prototyping
- Dedicated inference endpoints with autoscaling
- Text Generation Inference (TGI) for optimized LLM serving
Best for
SaaS teams that need access to the broadest range of models and want a single platform for discovery, evaluation, and deployment.
7. Fireworks AI
Fireworks AI optimizes inference speed and cost. Their custom inference engine delivers some of the lowest latencies in the market for popular models like Llama, Mixtral, and FLUX. For SaaS products where response time directly impacts user experience, Fireworks offers a meaningful advantage over general-purpose providers. Teams running batch image generation at scale benefit from their throughput optimizations.
Key strengths
- Purpose-built inference engine for minimal latency
- Competitive per-token and per-image pricing
- Function calling and structured JSON output
- On-demand and reserved capacity options
Best for
High-traffic SaaS products where every millisecond of latency and every cent of inference cost matters.
8. Together AI
Together AI focuses on open-source model hosting with strong support for fine-tuning and custom training. Their platform lets you fine-tune Llama, Mistral, or FLUX models on your own data and serve them via API. For SaaS products that need a branded, custom AI experience rather than generic model outputs, Together AI provides the tooling. Combining Together AI with a visual AI pipeline builder gives you the best of both worlds.
Key strengths
- Fine-tuning support for leading open-source models
- Serverless and dedicated inference endpoints
- Competitive pricing on open-source models
- Red Pajama and custom training data support
Best for
SaaS teams that want to fine-tune open-source models on proprietary data and serve them at scale.
Comparison Table
| Platform | Modalities | Pricing Model | Fine-tuning | Latency | Best For |
|---|---|---|---|---|---|
| Wireflow | Text, image, video, audio | Per-workflow execution | Via connected models | Low (parallel nodes) | Multi-model pipelines |
| OpenAI API | Text, image, audio | Per-token / per-image | Yes (GPT fine-tuning) | Medium | General-purpose AI |
| Anthropic Claude | Text | Per-token | No | Medium | Long-context text |
| FAL AI | Image, video, audio | Per-second compute | No | Very low | Fast media generation |
| Replicate | All (community models) | Per-second GPU | Yes (Cog) | Variable | Open-source flexibility |
| Hugging Face | All (500K+ models) | Free tier + dedicated | Yes | Variable | Model variety |
| Fireworks AI | Text, image | Per-token / per-image | Yes | Very low | Speed-critical apps |
| Together AI | Text, image | Per-token | Yes | Low | Custom fine-tuned models |
How to Choose the Right Platform
The right platform depends on what kind of AI generation your SaaS product needs. If you are building a single-model integration like a chatbot or an image generator, a direct API like OpenAI or FAL AI keeps things simple. If your product needs AI pipeline automation that chains multiple models together, such as generating text then converting it to an image then upscaling, a pipeline tool reduces integration complexity significantly.
Consider these factors when evaluating:
- Modality needs: Text-only products can use any LLM provider. Multi-modal products benefit from platforms that support image, video, and audio under one roof.
- Latency requirements: Real-time features need sub-second inference (FAL AI, Fireworks). Async batch jobs are fine with any provider.
- Customization depth: If generic model outputs are not enough, choose a platform with fine-tuning support or custom model hosting.
- Scale trajectory: Start with serverless pay-per-use pricing. Move to reserved capacity once traffic patterns stabilize.
Try It Yourself
Try it yourself: Build this workflow in Wireflow. The nodes are pre-configured with the exact text-to-image pipeline discussed above, so you can see how visual AI workflow building works in practice.
FAQ
What does it mean to embed AI generation in a SaaS product?
Embedding AI generation means integrating AI models directly into your SaaS application so users can generate text, images, video, or audio without leaving your product. This is done through APIs that connect your frontend or backend to AI inference services.
Which platform is best for embedding image generation in SaaS?
For single-model image generation, FAL AI offers the fastest inference. For multi-step image pipelines that combine generation, editing, and upscaling, Wireflow's workflow API lets you chain everything into one endpoint.
Do I need to manage GPUs to embed AI generation?
No. All eight platforms listed here are fully managed or serverless. You call an API and receive results without provisioning or maintaining GPU infrastructure.
How much does embedded AI generation cost for a SaaS product?
Costs vary by modality and volume. Text generation typically runs $0.50 to $15 per million tokens. Image generation ranges from $0.01 to $0.10 per image. Most platforms offer pay-per-use pricing so you only pay for actual generation.
Can I use multiple AI providers in one SaaS product?
Yes. Many SaaS products use different providers for different tasks, such as OpenAI for chat and FAL AI for images. Tools like Wireflow's visual node editor let you combine multiple providers into a single workflow without writing integration code for each one.
What is the difference between serverless and dedicated AI inference?
Serverless inference scales to zero when idle and bills per request. Dedicated inference reserves GPU capacity for consistent performance. Start serverless for development and switch to dedicated once your traffic is predictable.
How do I handle rate limits when embedding AI generation?
Most providers offer queue-based architectures with webhook callbacks for async processing. Build your integration to submit generation requests and poll or receive callbacks rather than blocking on synchronous responses.
Is it possible to fine-tune AI models for my SaaS product?
Yes. Together AI, Replicate, Hugging Face, and OpenAI all support fine-tuning. This lets you train models on your product's specific data to improve output quality and consistency for your users.


