
Choosing the right AI API determines how quickly you can ship production features and how much you spend doing it. Wireflow gives developers a unified REST API to chain 150+ AI models (image, video, audio, text) with a single auth token, so you can build complex generative pipelines without stitching together five separate SDKs. Below, we compare eight leading AI API platforms across pricing, model coverage, latency, and developer experience.
Quick Summary
- Wireflow - Best overall for multi-model workflows via one API
- OpenAI - Best for LLM-first applications (GPT-4o, DALL-E)
- Anthropic - Best for long-context reasoning (Claude 4)
- Google Gemini - Best for multimodal input (text, image, video, audio)
- Replicate - Best for open-source model access
- Hugging Face - Best for ML research and custom models
- Together AI - Best for fast open-model inference
- FAL AI - Best for real-time media generation
1. Wireflow
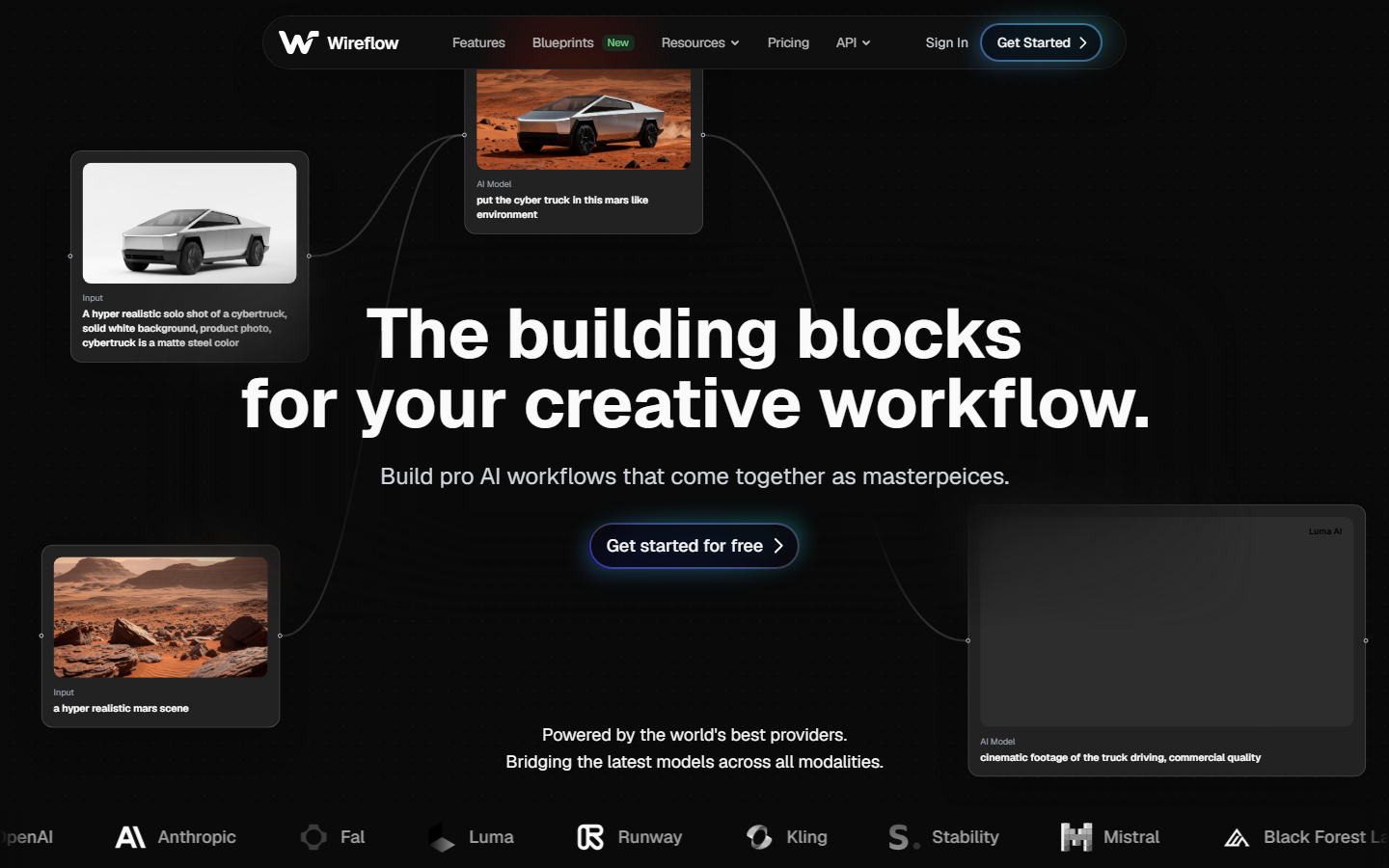
Wireflow is a visual workflow platform that exposes every canvas operation as a REST endpoint. Instead of managing separate API keys for image generation, video synthesis, and audio processing, you build a workflow in the node editor and call it with one POST /workflows/{id}/execute request.
Key features:
- 157 node types across image, video, audio, 3D, and text generation
- Async execution with polling or webhook callbacks
- Rate limits from 10 req/min (Free) to 200 req/min (Enterprise)
- Idempotency keys prevent duplicate executions
- Published workflows become callable "Apps" with their own endpoints
Authentication uses Bearer tokens (prefix sk-) with granular scopes: workflows:read, workflows:write, workflows:execute, executions:read.
curl -X POST https://www.wireflow.ai/api/v1/workflows/YOUR_ID/execute \
-H "Authorization: Bearer sk-your-api-key" \
-H "Content-Type: application/json" \
-d '{"nodes": [...], "edges": []}'
Pricing: Free tier includes 50 daily executions. Pro tier at $29/month unlocks 1,000 daily executions and priority queuing. Full breakdown at the pricing page.
2. OpenAI
OpenAI remains the default choice for text generation. GPT-4o handles text, images, and audio in a single model call, while GPT-4o-mini delivers similar capabilities at $0.15 per million input tokens, a 16x cost reduction compared to the full model.
Strengths: Mature SDK ecosystem (Python, Node, .NET), function calling, structured outputs, real-time streaming via WebSockets. The Assistants API adds persistent threads and file search for chatbot use cases.
Limitations: Closed-source models only. Image generation (DALL-E 3) lags behind specialized providers in quality. Rate limits can be restrictive on lower tiers.
3. Anthropic (Claude)

Anthropic focuses on safety-first AI with Claude 4 models. The 200K context window (1M for Opus) makes it the top pick for document analysis, code generation, and complex reasoning tasks.
Strengths: Low hallucination rates, tool use, computer use capabilities, extended thinking mode for multi-step problem solving.
Pricing: Claude 4 Haiku at $0.25/$1.25 per million tokens (input/output) offers strong value for high-volume applications.
4. Google Gemini
Google Gemini accepts text, images, video, audio, and PDFs natively. Gemini 2.5 Flash supports 1M input tokens with a generous free tier (500 requests/day via AI Studio).
Strengths: Native multimodal understanding without preprocessing, Grounding with Google Search, code execution capabilities, and tight integration with Vertex AI for enterprise deployments.
Limitations: Output quality for creative writing trails behind Claude and GPT-4o.
5. Replicate
Replicate hosts thousands of open-source models behind a uniform REST API. Pay per second of compute. Ideal for developers who want access to Flux, Stable Diffusion, LLaMA, and Whisper without managing GPU infrastructure.
Strengths: Run any model with replicate.run(), custom model deployment via Cog, automatic scaling to zero when idle.
Limitations: Cold starts on less-popular models can add 10-30 seconds of latency. No SLA on free tier.
6. Hugging Face Inference API
Hugging Face offers 300,000+ models through its Inference API. Best for teams that want to experiment with bleeding-edge research models or deploy fine-tuned versions of open-source architectures.
Strengths: Largest model repository, Inference Endpoints for dedicated GPUs, Spaces for demo apps, Transformers.js for client-side inference.
Limitations: Inference API rate limits are strict on free tier. Production workloads need dedicated endpoints ($0.06/hr+).
7. Together AI
Together AI specializes in fast inference for open models. Their custom infrastructure delivers sub-200ms time-to-first-token for LLaMA 3 and Mixtral, making it a strong choice for latency-sensitive applications.
Strengths: Competitive pricing ($0.20/M tokens for smaller models), JSON mode, function calling, fine-tuning API, and batch inference for high-volume workloads.
Limitations: Model selection smaller than Replicate or Hugging Face. Focused primarily on text and image models.
8. FAL AI
FAL AI targets real-time media generation with sub-second inference on image models. Their queue-based architecture handles burst traffic well, and the serverless GPU infrastructure scales automatically.
Strengths: Fastest Flux inference available, real-time image generation endpoints, built-in CDN for generated assets, WebSocket streaming for progressive rendering.
Limitations: Focused on media generation; no LLM or audio models. Pricing can scale quickly for high-resolution batch jobs.
Comparison Table
| Platform | Model Types | Free Tier | Auth Method | Async Support | Webhook Triggers |
|---|---|---|---|---|---|
| Wireflow | Image, Video, Audio, Text, 3D | 50 exec/day | Bearer (sk-) | Yes (polling) | Yes |
| OpenAI | Text, Image, Audio, Embedding | $5 credit | Bearer | Batch API | No |
| Anthropic | Text | $5 credit | x-api-key | No | No |
| Google Gemini | Text, Image, Video, Audio | 500 req/day | API key | No | No |
| Replicate | All (open-source) | Limited | Bearer | Yes (webhooks) | No |
| Hugging Face | All (300K+ models) | Rate-limited | Bearer | Endpoints only | No |
| Together AI | Text, Image | $5 credit | Bearer | Batch API | No |
| FAL AI | Image, Video | Queue-based | Key-based | Yes (queue) | No |
How to Choose the Right AI API
The best platform depends on your use case:
- Multi-model pipelines (image + video + text in one call): Wireflow handles the orchestration so you write one API call instead of five.
- LLM-only apps (chatbots, summarization, code generation): OpenAI or Anthropic give you the highest-quality text models with mature tooling.
- Multimodal understanding (analyzing images/video/audio): Google Gemini accepts everything natively.
- Open-source flexibility (custom models, fine-tuning): Replicate or Hugging Face let you run anything without vendor lock-in.
- Latency-critical media generation (real-time image previews): FAL AI or Together AI optimize for speed.
Consider also whether you need webhook-based triggers for event-driven architectures, or if synchronous request-response fits your stack better. Wireflow's webhook endpoint accepts unauthenticated POST requests, which simplifies integration with form builders and CI pipelines.
Try it yourself: Open this workflow in Wireflow to see the nodes pre-configured to generate a product photo from a text prompt via the API, demonstrating how a single execute call produces real output.
FAQ
What is the best AI API for beginners?
Google Gemini offers the most generous free tier (500 requests/day) with a simple API key authentication. The AI Studio playground lets you test prompts before writing code.
Can I use multiple AI APIs in one application?
Yes. Platforms like Wireflow let you chain multiple AI models in a single workflow, called via one API endpoint. Alternatively, you can integrate multiple providers manually using their individual SDKs.
What is the cheapest AI API for production use?
For text generation, GPT-4o-mini at $0.15/M input tokens or Claude Haiku at $0.25/M offer the best cost-per-quality ratio. For image generation, FAL AI and Replicate charge per-second of compute rather than flat per-image rates.
Do AI APIs support real-time streaming?
OpenAI, Anthropic, and Google Gemini all support server-sent events (SSE) for token streaming. Wireflow supports async polling with configurable intervals. FAL AI offers WebSocket connections for progressive image rendering.
What authentication methods do AI APIs use?
Most platforms use Bearer token authentication via HTTP headers. Google Gemini also supports API key authentication for simpler setups. Wireflow uses scoped Bearer tokens with granular permissions (read, write, execute).
How do rate limits work across AI API providers?
Rate limits vary by plan. Free tiers typically allow 10-60 requests per minute. Enterprise plans offer 200+ req/min. Most providers return 429 Too Many Requests with a Retry-After header when limits are exceeded.
Can I trigger AI API calls from webhooks?
Wireflow supports no-auth webhook triggers (POST to /workflow/{webhookId}/trigger) that start workflow executions without API keys, making it easy to connect from Zapier, CI/CD, or form submissions. Most other providers require authentication on every call.
What happens when an AI API call fails?
Standard practice is exponential backoff with retry. Check the HTTP status: 429 means rate limited (wait and retry), 402 means insufficient credits, 500 means server error (retry after delay). Wireflow returns structured error objects with context fields for debugging.
Conclusion
The AI API landscape in 2026 offers specialized solutions for every use case. For developers building applications that need multiple AI capabilities in a single pipeline, Wireflow consolidates the complexity into one authenticated endpoint with built-in orchestration, polling, and webhook support.


