
If you need to generate images at scale through code, the right platform can save you months of integration work. Wireflow combines a visual node-based canvas with a full REST API, letting developers build image generation pipelines they can trigger from any codebase. Below, we compare the seven strongest programmatic image generation platforms available in 2026, covering pricing, model access, and API workflow capabilities.
Quick Summary
- Wireflow - Best Overall (visual canvas + REST API hybrid)
- fal.ai - Best for Model Variety (1,000+ models via unified API)
- Replicate - Best for Open Source (per-second billing, community models)
- Leonardo AI - Best for Creative Teams (image + video in one API)
- Stability AI - Best for Self-Hosting (SD3 API + on-prem option)
- Segmind - Best for Budget (low per-image pricing, serverless)
- RunPod - Best for Custom Infrastructure (GPU rental + API endpoints)
1. Wireflow
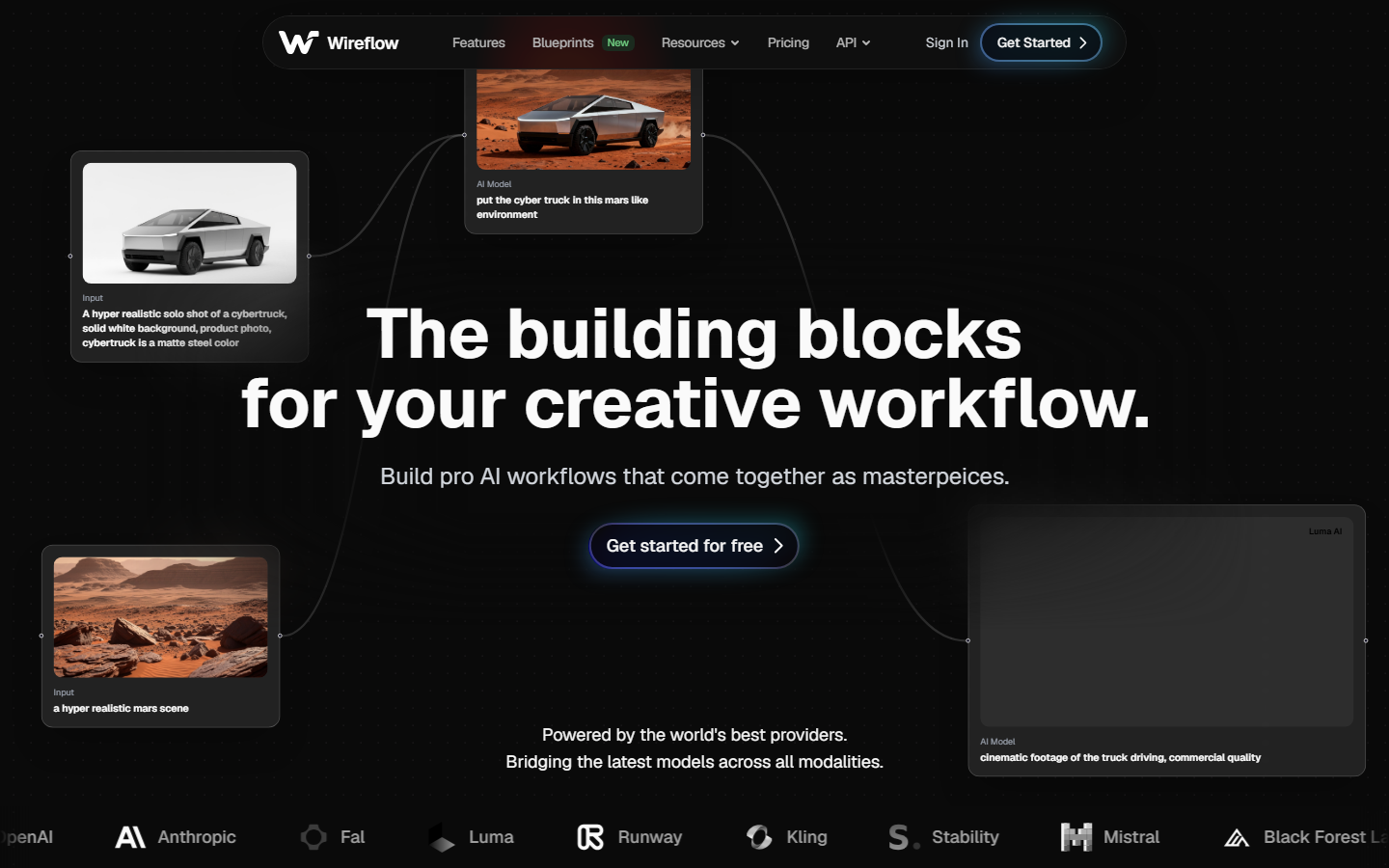
Wireflow is a node-based AI workflow platform that exposes every canvas workflow as a callable REST endpoint. You can chain models like Flux 2 Pro, Imagen 4, and Recraft V4 into multi-step pipelines, then execute them via POST /api/v1/workflows/{id}/execute. For a hands-on look at this in action, check out the programmatic image generation feature page.
What sets Wireflow apart is the dual interface. You design workflows visually on the no-code canvas, then call them programmatically with a single API request. The platform supports webhook triggers (no API key required for external integrations), idempotency keys for safe retries, and async execution with polling. Rate limits scale from 10 requests/minute on the free tier to 200/minute on Enterprise. Batch processing is built in, so you can generate hundreds of images per workflow run through batch generation nodes.
Pricing starts free with 50 daily executions, scaling to unlimited on Enterprise plans.
2. fal.ai
fal.ai provides a unified API gateway to over 1,000 AI models, including Flux 2 Pro, Stable Diffusion 3, and proprietary models from smaller labs. The platform handles cold starts aggressively, often returning results in under 2 seconds for popular models. You pay per inference with no subscription lock-in, and the REST API follows a straightforward request/response pattern.
fal.ai is strongest when you need access to many different models through a single integration point. However, it lacks a visual workflow builder, so chaining multiple models requires custom orchestration code on your side. Pricing varies by model, typically $0.01-0.05 per image depending on resolution and model tier.
3. Replicate
Replicate pioneered the "push a model, get an API" concept. It hosts thousands of open-source models contributed by the community, including fine-tuned variants of Flux, SDXL, and specialized models for product photography, illustration, and architecture rendering. Billing is per-second of GPU time, which means you only pay for actual compute. The platform supports model chaining through its predictions API, where one model's output feeds into the next.
Replicate works well for teams that need access to niche or custom-trained models. The trade-off is that cold starts for less popular models can take 10-30 seconds, and there is no built-in visual editor for designing workflows.
4. Leonardo AI
Leonardo AI targets creative teams with an API that covers both image and video generation. The platform includes its own fine-tuned models alongside access to Flux and Stable Diffusion variants. Unique features include real-time canvas generation, image editing capabilities, and style transfer through the API.
Leonardo is a solid choice for teams that need both a consumer-friendly UI for designers and API access for developers. The API supports batch operations and webhook callbacks. Pricing follows a credit-based system with plans starting at $12/month for 8,500 credits.
5. Stability AI
Stability AI offers direct API access to Stable Diffusion 3 and its newer models, plus a self-hosting option for teams that need on-premises deployment. The API supports text-to-image, image-to-image, inpainting, and outpainting through clean REST endpoints. If you are generating at high volume, self-hosting on your own GPUs can reduce per-image costs to under $0.005. Their image generation API documentation covers integration patterns for both managed and self-hosted deployments.
The main draw is cost control at scale. Teams generating over 50,000 images monthly often find self-hosting more economical than any managed platform.
6. Segmind
Segmind positions itself as a budget-friendly serverless inference platform. It hosts popular models including Flux, SDXL, and several specialized models for product photography and e-commerce. Pricing starts as low as $0.003 per image, making it one of the cheapest options for production-scale image generation.
Segmind also offers a visual workflow builder (Pixelflow) for chaining models without code, though its API capabilities are more limited than platforms built API-first. The platform supports ComfyUI workflow imports, which is useful for teams migrating from local ComfyUI setups.
7. RunPod
RunPod provides GPU rental with serverless endpoint deployment. You can deploy any Docker container as an API endpoint, which makes it highly flexible for custom model serving. Popular configurations include Flux, SDXL, and ComfyUI workflows exposed as REST APIs. Pricing is per-second of GPU time, starting at $0.00016/second for an RTX 4090. The platform suits teams with specific infrastructure needs or those running heavily customized AI pipeline configurations.
RunPod requires more setup than managed platforms. You handle model loading, scaling configuration, and health monitoring. In return, you get full control over the runtime environment and competitive GPU pricing.
Comparison Table
| Platform | Models Available | Pricing Model | Visual Builder | Self-Host | Batch Support | Webhook Triggers |
|---|---|---|---|---|---|---|
| Wireflow | 157+ (Flux, Imagen, Recraft, etc.) | Per-execution credits | Yes (node canvas) | No | Yes | Yes |
| fal.ai | 1,000+ | Per-inference | No | No | Yes | Yes |
| Replicate | 5,000+ (community) | Per-second GPU | No | No | Yes | Yes |
| Leonardo AI | 20+ (proprietary + open) | Credit packs | Yes (canvas) | No | Yes | Yes |
| Stability AI | 5-10 (own models) | Per-image or self-host | No | Yes | Yes | No |
| Segmind | 100+ | Per-image | Yes (Pixelflow) | No | Yes | No |
| RunPod | Any (Docker) | Per-second GPU | No | Yes (your GPU) | Yes | Yes |
How to Choose the Right Platform
The decision usually comes down to three factors: how many models you need, whether you want a visual builder, and your monthly generation volume. If you need a single integration that handles orchestration, chaining, and batch processing with both a canvas and API, Wireflow covers the widest range of use cases. For pure model variety, fal.ai and Replicate offer the largest catalogs. For cost control at very high volumes, self-hosting through Stability AI or RunPod is the most economical path.
Consider your team's workflow too. Platforms with visual builders reduce the gap between prototyping and production, since designers can build workflows that developers then call via API. This hybrid approach eliminates the traditional handoff friction between creative and engineering teams.
A Quick API Example
Here is a minimal curl example showing how to trigger an image generation workflow via the Wireflow API. This pattern, POST to execute then GET to poll, works across most platforms with minor variations in endpoint structure:
curl -X POST https://www.wireflow.ai/api/v1/workflows/YOUR_WORKFLOW_ID/execute \
-H "Authorization: Bearer sk-your-api-key" \
-H "Content-Type: application/json" \
-d '{"nodes": [...], "edges": []}'
Poll for results with exponential backoff until the status returns COMPLETED. The full execution flow, including error handling and rate limits, is documented in the API reference.
Try it yourself: Build this workflow in Wireflow - the nodes are pre-configured with a text-to-image pipeline using Flux 2 Pro, ready to execute from the canvas or via API.
Frequently Asked Questions
What is programmatic image generation?
Programmatic image generation means creating images through code rather than a manual interface. You send a text prompt or parameters to an API endpoint, and the platform returns a generated image. This approach allows automation, batch processing, and integration with existing software systems.
Which platform is best for high-volume image generation?
For volumes above 50,000 images per month, self-hosting through Stability AI or RunPod typically offers the lowest per-image cost. For moderate volumes (1,000-50,000/month), managed platforms like Wireflow or fal.ai provide better economics when you factor in maintenance overhead.
Can I chain multiple AI models in a single API call?
Yes. Wireflow supports model chaining natively through its node-based workflow system. You can connect a text-to-image model to an upscaler, background remover, or style transfer model, then execute the entire chain with one API request.
Do these platforms support webhook notifications?
Wireflow, fal.ai, Replicate, and RunPod all support webhook callbacks for async workflows. This lets you trigger a generation job and receive the result at a URL you specify, without needing to poll. Wireflow's webhook endpoint requires no API key, making it easy to connect with tools like Zapier or CI systems.
What image formats do programmatic generation APIs support?
Most platforms return PNG or JPEG by default. Some, including fal.ai and Replicate, also support WebP output. Wireflow's content generation API returns URLs to generated images hosted on CDN storage, which you can download in the original format or convert as needed.
How do I handle rate limits when generating images at scale?
All major platforms enforce rate limits. Wireflow returns standard X-RateLimit-Remaining and Retry-After headers on every response. The recommended pattern is exponential backoff: start at 1 second between retries, multiply by 1.5 per attempt, and cap at 10 seconds. For consistent high throughput, consider the Pro or Enterprise tier which offers 60-200 requests/minute.
Is there an SDK for these platforms?
fal.ai, Replicate, and Leonardo AI offer official Python and/or Node.js SDKs. Wireflow and Stability AI use plain REST with no official SDK, which means any HTTP client (curl, fetch, axios, requests) works out of the box. The trade-off is less abstraction but zero dependency on SDK maintenance cycles.
Can I fine-tune models through these APIs?
Replicate and Leonardo AI support custom model fine-tuning through their APIs. Segmind offers DreamBooth and LoRA training for custom image generation models. Wireflow and fal.ai focus on inference rather than training, relying on their broad model catalogs to cover most use cases without fine-tuning.


