
Choosing the right AI generation platform can make or break your development workflow. Whether you need text-to-image APIs, video synthesis, or multi-model pipelines, the platforms below offer the best combination of performance, documentation, and developer experience. Wireflow lets you visually chain multiple AI models into production-ready workflows with full API access, so you spend less time on infrastructure and more time shipping.
Quick summary:
- Wireflow - Best overall for visual AI pipelines with API
- Replicate - Best for running open-source models via API
- fal.ai - Best for real-time image generation
- Hugging Face - Best for model discovery and inference
- Together AI - Best for fast LLM and diffusion inference
- RunPod - Best for GPU-first serverless workloads
- Modal - Best for custom Python AI workloads
- Fireworks AI - Best for low-latency LLM serving
1. Wireflow - Visual AI Pipelines with Full API
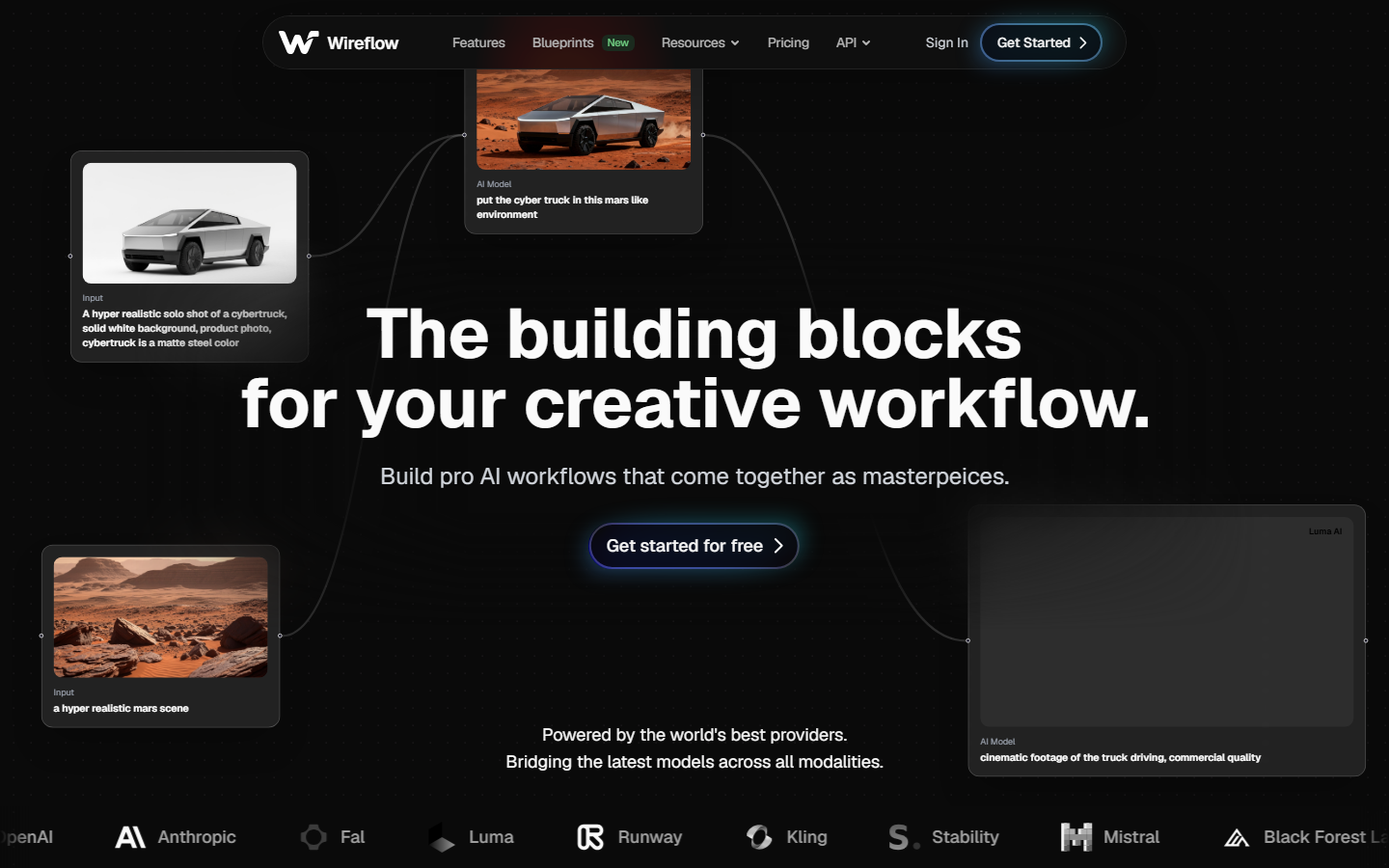
Wireflow gives developers a no-code canvas for building multi-step AI generation workflows, backed by a REST API that can trigger any workflow programmatically. You drag models like Recraft V4, Kling Video, or Flux onto a canvas, wire them together, and deploy the entire pipeline as a single API endpoint.
For a hands-on look at this in action, check out the AI workflow builder feature page.
Key strengths include model chaining across image, video, and audio models, batch generation for processing hundreds of assets at once, and a built-in visual node editor that makes debugging pipelines straightforward. Pricing starts free with pay-per-run on generation nodes.
2. Replicate - Open-Source Models via API
Replicate hosts thousands of open-source models behind a unified API. You push a model with Cog (their containerization tool), and Replicate handles scaling, GPU provisioning, and cold starts. Their prediction API returns results via webhooks or polling, and they support streaming for compatible models.
The platform is strongest for teams that want to test many models quickly without managing infrastructure. Pricing is per-second of GPU time, which keeps experimentation cheap. The model marketplace ecosystem is large, covering Stable Diffusion variants, LLaMA fine-tunes, audio models, and video generators.
3. fal.ai - Real-Time Image and Video Generation
fal.ai focuses on speed. Their serverless GPU infrastructure is optimized for sub-second inference on popular diffusion models, with SDKs for Python, JavaScript, and Swift. The queue-based API handles burst traffic well, and their real-time endpoints support streaming partial results as they render.
fal.ai also offers a canvas-style editor for non-developers, but the real value is the API layer. Cold starts are minimal compared to competitors, and they maintain optimized versions of Flux, SDXL, and several video models. Pay-per-request pricing scales linearly.
4. Hugging Face - Model Hub and Inference API
Hugging Face is the default discovery layer for open-source AI. Their Inference API provides hosted endpoints for thousands of models, and Inference Endpoints lets you deploy dedicated instances on your choice of GPU. The Transformers library remains the standard for model loading and fine-tuning in Python.
For generation tasks specifically, Hugging Face offers Spaces where developers demo models with Gradio UIs, plus a Pro tier with higher rate limits and priority access to popular models. The ecosystem's breadth is unmatched, though latency on the free inference tier can be inconsistent.
5. Together AI - Fast Inference for LLMs and Diffusion
Together AI runs optimized inference clusters for both language models and image generators. Their API is OpenAI-compatible for chat completions, which simplifies migration. For image generation, they host Flux and SDXL variants with competitive pricing per image.
The platform shines on throughput. If you need to generate thousands of images or run batch LLM calls, Together AI's infrastructure handles the concurrency without manual scaling. Fine-tuning is available for supported models, and they publish transparent benchmarks on tokens-per-second and time-to-first-token.
6. RunPod - Serverless GPUs for AI Workloads
RunPod provides serverless and dedicated GPU instances optimized for AI inference and training. Their Serverless product lets you deploy Docker containers that auto-scale based on request volume, with support for A100, H100, and consumer GPUs at competitive per-second rates.
RunPod is the best fit when you need raw GPU access with minimal abstraction. Their template marketplace includes pre-configured environments for ComfyUI, Stable Diffusion WebUI, and custom model serving. Networking between pods is fast, making multi-GPU training setups practical.
7. Modal - Python-Native Serverless AI
Modal takes a code-first approach. You write standard Python functions, decorate them with Modal's SDK, and the platform handles containerization, GPU scheduling, and scaling. There are no Dockerfiles to manage. Their @web_endpoint decorator turns any function into a REST API instantly.
For developers building custom generation pipelines, Modal offers fine-grained control over dependencies, volumes for model weights, and cron scheduling for batch jobs. The developer experience is polished: local testing works out of the box, and deploy times are fast. Pricing is per-second of compute with clear GPU tiers.
8. Fireworks AI - Low-Latency Model Serving
Fireworks AI specializes in serving fine-tuned and quantized models with minimal latency. Their FireAttention engine optimizes transformer inference, and the API supports function calling, JSON mode, and structured outputs natively. For image generation, they host Flux and SDXL with fast cold starts.
The platform targets production teams that need reliable, low-latency endpoints. SLA-backed uptime, dedicated deployments, and on-demand fine-tuning make Fireworks a strong choice for applications where generation speed directly impacts user experience.
Comparison Table
| Platform | Best For | API Style | Image Gen | Video Gen | Pricing Model |
|---|---|---|---|---|---|
| Wireflow | Visual AI pipelines | REST + Canvas | Yes | Yes | Free + per-run |
| Replicate | Open-source models | REST + Webhooks | Yes | Yes | Per-second GPU |
| fal.ai | Real-time generation | REST + Queue | Yes | Yes | Per-request |
| Hugging Face | Model discovery | REST + Python SDK | Yes | Limited | Free tier + Pro |
| Together AI | Batch inference | OpenAI-compatible | Yes | No | Per-token/image |
| RunPod | Raw GPU access | REST + Docker | Yes | Yes | Per-second GPU |
| Modal | Custom Python | Python SDK | Yes | Yes | Per-second compute |
| Fireworks AI | Low-latency serving | REST + OpenAI-compat | Yes | No | Per-token/image |
How to Choose the Right Platform
Picking a platform depends on three factors: your team's technical depth, the models you need, and how much infrastructure you want to manage.
If you want a visual builder with API access for orchestrating multiple AI models, a canvas-based approach saves significant development time. If you prefer writing Python and handling containers yourself, serverless GPU platforms give you maximum flexibility.
For teams evaluating cost, pay-per-request platforms (fal.ai, Together AI) are simpler to budget for, while per-second GPU billing (Replicate, RunPod) rewards optimization but can surprise you if cold starts are frequent. Consider running a proof-of-concept on two or three platforms before committing, since API integration patterns vary enough that switching later is non-trivial.
Documentation quality matters more than feature counts. Platforms with clear quickstart guides, working code samples, and responsive communities (Hugging Face, Modal, Replicate) reduce onboarding time significantly. Check each platform's status page history for uptime patterns before relying on it for production workloads.
Try it yourself: Build this workflow in Wireflow to see how a text-to-image generation and upscaling pipeline works with pre-configured nodes.
FAQ
What makes an AI generation platform "developer-friendly"?
A developer-friendly platform provides clear API documentation, SDKs in popular languages (Python, JavaScript, Go), predictable pricing, fast cold starts, and webhook or streaming support for async generation tasks. Good error messages and sandbox environments also matter.
Can I use multiple AI generation platforms together?
Yes. Many teams use one platform for image generation and another for LLM inference. Tools like pipeline builders let you chain calls across providers without writing custom orchestration code.
Which platform has the lowest latency for image generation?
fal.ai consistently benchmarks among the fastest for Flux and SDXL inference, with sub-2-second generation times. Fireworks AI is competitive for smaller models. Latency depends on model size, so test with your specific use case and read about the latest API options for comparison.
Are there free tiers available?
Most platforms offer free tiers or credits. Hugging Face provides free inference API access with rate limits. Replicate gives new users credits to test models. Wireflow includes a free tier with pay-per-run pricing. RunPod and Modal offer initial compute credits for new accounts.
How do I handle rate limits in production?
Use queue-based architectures with retry logic and exponential backoff. Most platforms return standard HTTP 429 responses with retry-after headers. For high-volume workloads, consider dedicated endpoints or reserved capacity plans that guarantee throughput.
What about data privacy and model security?
Check each platform's data retention policy. Some platforms (Modal, RunPod) let you run models in isolated containers where inputs never leave your environment. Others (Replicate, fal.ai) process inputs on shared infrastructure but delete data after pipeline execution. For regulated industries, look for SOC 2 compliance and VPC deployment options.
Can I fine-tune models on these platforms?
Together AI, Replicate, and Hugging Face offer built-in fine-tuning workflows. Modal and RunPod give you raw GPU access for custom training scripts. Fireworks AI supports LoRA-based fine-tuning for supported model architectures. The cost and complexity vary significantly by platform.
Which platform is best for video generation APIs?
For video generation, platforms that host Kling, Veo, or similar models are your best bet. Replicate and fal.ai host several video models. Wireflow supports video workflows with models like Kling Video and Seedance natively in the node editor.


